Hirschman uncertainty
In quantum mechanics, information theory, and Fourier analysis, the Hirschman uncertainty is defined as the sum of the temporal and spectral Shannon entropies. It turns out that Heisenberg's uncertainty principle can be expressed as a lower bound on the sum of these entropies. This is stronger than the usual statement of the uncertainty principle in terms of the product of standard deviations.
In 1957,[1] Hirschman considered a function f and its Fourier transform g such that
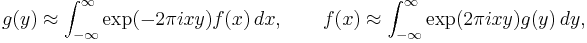
where the "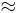 " indicates convergence in
" indicates convergence in  , and normalized so that (by Plancherel's theorem)
, and normalized so that (by Plancherel's theorem)
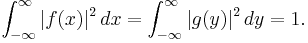
He showed that for any such functions the sum of the Shannon entropies is non-negative:
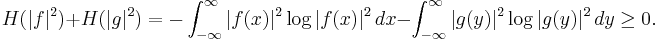
A tighter bound,
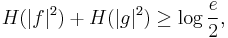
was conjectured by Hirschman[1] and Everett[2] and proven in 1975 by W. Beckner.[3]. The equality holds in the case of Gaussian distributions[4],
Contents |
Sketch of proof
The proof of this tight inequality depends on the so-called (q, p)-norm of the Fourier transformation. (Establishing this norm is the most difficult part of the proof.) From this norm we are able to establish a lower bound on the sum of the (differential) Rényi entropies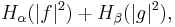 where
where 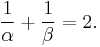 For simplicity we shall consider this inequality only in one dimension; the extension to multiple dimensions is not difficult and can be found in the literature cited.
For simplicity we shall consider this inequality only in one dimension; the extension to multiple dimensions is not difficult and can be found in the literature cited.
Babenko–Beckner inequality
The (q, p)-norm of the Fourier transform is defined to be[5]
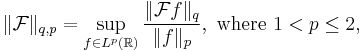 and
and 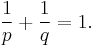
In 1961, Babenko[6] found this norm for even integer values of q. Finally, in 1975, using Hermite functions as eigenfunctions of the Fourier transform, Beckner[3] proved that the value of this norm (in one dimension) for all 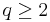 is
is
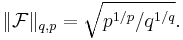
Thus we have the Babenko–Beckner inequality that
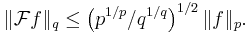
Rényi entropy inequality
From this inequality, an expression of the uncertainty principal in terms of the Rényi entropy can be derived.[5][7]
Letting 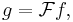
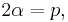 and
and 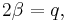 so that
so that 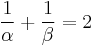 and
and 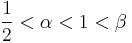 we have
we have
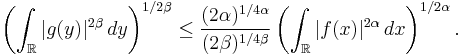
Squaring both sides and taking the logarithm, we get:
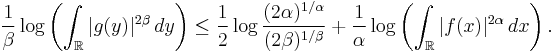
Multiplying both sides by 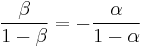 reverses the sense of the inequality:
reverses the sense of the inequality:
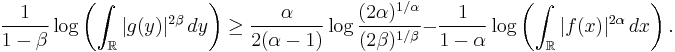
Rearranging terms, we finally get an inequality in terms of the sum of the Rényi entropies:
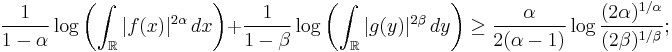
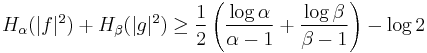
Note that this inequality is symmetric with respect to  and
and 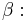 We no longer have to assume that
We no longer have to assume that 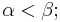 only that they are positive and not both one, and that
only that they are positive and not both one, and that 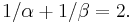 To see this symmetry, simply exchange the rôles of
To see this symmetry, simply exchange the rôles of  and
and 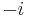 in the Fourier transform.
in the Fourier transform.
Shannon entropy inequality
Taking the limit of this last inequality as 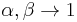 yields the Shannon entropy inequality
yields the Shannon entropy inequality
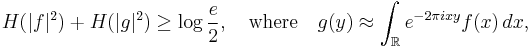
valid for any base of logarithm as long as we choose an appropriate unit of information, bit, nat, etc. The constant will be different, though, for a different normalization of the Fourier transform, (such as is usually used in physics,) i.e.
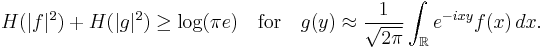
In this case the dilation of the Fourier transform by a factor of 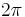 simply adds
simply adds 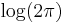 to its entropy.
to its entropy.
Entropy versus variance
The Gaussian or normal probability distribution plays an important role in the relationship between variance and entropy: it is a problem of the calculus of variations to show that this distribution maximizes entropy for a given variance, and at the same time minimizes the variance for a given entropy. Moreover the Fourier transform of a Gaussian probability amplitude function is also Gaussian—and the absolute squares of both of these are Gaussian, too. This suggests—and it is in fact quite true—that the entropic statement of the uncertainty principle is stronger than its traditional statement in terms of the variance or standard deviation.
Hirschman[1] explained that entropy—his version of entropy was the negative of Shannon's—is a "measure of the concentration of [a probability distribution] in a set of small measure." Thus a low or large negative Shannon entropy means that a considerable mass of the probability distribution is confined to a set of small measure. Note that this set of small measure need not be contiguous; a probability distribution can have several concentrations of mass in intervals of small measure, and the entropy may still be low no matter how widely scattered those intervals are.
This is not the case with the variance: variance measures the concentration of mass about the mean of the distribution, and a low variance means that a considerable mass of the probability distribution is concentrated in a contiguous interval of small measure.
To make this distinction more formal, we say that two probability density functions 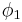 and
and 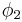 are equimeasurable if:
are equimeasurable if:
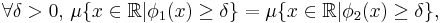
where 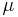 is the Lebesgue measure. Any two equimeasurable probability density functions have the same Shannon entropy, and in fact the same Rényi entropy of any order. The same is not true of variance, however. Any probability density function has a radially decreasing equimeasurable "rearrangement" whose variance is less (up to translation) than any other rearrangement of the function; and there exist rearrangements of arbitrarily high variance, (all having the same entropy.)
is the Lebesgue measure. Any two equimeasurable probability density functions have the same Shannon entropy, and in fact the same Rényi entropy of any order. The same is not true of variance, however. Any probability density function has a radially decreasing equimeasurable "rearrangement" whose variance is less (up to translation) than any other rearrangement of the function; and there exist rearrangements of arbitrarily high variance, (all having the same entropy.)
In fact, for any probability density function 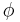 on the real line,
on the real line,
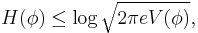
where H is the Shannon entropy and V is the variance, an inequality that is saturated only in the case of a normal distribution.
See also
References
- ^ a b c I.I. Hirschman, Jr., A note on entropy. American Journal of Mathematics (1957) pp. 152–156
- ^ Hugh Everett, III. The Many-Worlds Interpretation of Quantum Mechanics: the theory of the universal wave function. Everett's Dissertation
- ^ a b W. Beckner, Inequalities in Fourier analysis. Annals of Mathematics, Vol. 102, No. 6 (1975) pp. 159–182.
- ^ Ozaydin, Murad; Przebinda, Tomasz (2004). "An Entropy-based Uncertainty Principle for a Locally Compact Abelian Group". Journal of Functional Analysis (Elsevier Inc.) 215 (1): 241–252. http://redwood.berkeley.edu/w/images/9/95/2002-26.pdf. Retrieved 2011-06-23.
- ^ a b Iwo Bialynicki-Birula. Formulation of the uncertainty relations in terms of the Renyi entropies. arXiv:quant-ph/0608116v2
- ^ K.I. Babenko. An ineqality in the theory of Fourier analysis. Izv. Akad. Nauk SSSR, Ser. Mat. 25 (1961) pp. 531–542 English transl., Amer. Math. Soc. Transl. (2) 44, pp. 115-128
- ^ H.P. Heinig and M. Smith, Extensions of the Heisenberg–Weil inequality. Internat. J. Math. & Math. Sci., Vol. 9, No. 1 (1986) pp. 185–192. [1]
Further reading
- S. Zozor, C. Vignat. On classes of non-Gaussian asymptotic minimizers in entropic uncertainty principles. arXiv:math/0605510v1